
前言
这学期上了一门挺感兴趣的操作系统课,课程实践内容就是标题。但问题来了,教程里面给的是华为云和openEuler发行版的教程,这让我很不理解。毋庸置疑这项任务是非常有学习价值的,但这种冷门发行版很多操作都和主流发行版不同,与其说是学习,不如说是照本宣科完成一项死板的任务。而之后真正需要用到的时候,又要重新学习一遍其他发行版的流程,无形中增加了学习成本。不过毕竟大学的教育就是这样,不合理的教学已经司空见惯了
好在这次实验的核心其实和发行版关系不大,重点在于内核编译流程和系统调用的原理,只要保证方法正确,换环境不会影响结果。为了不让自己失去动力,从而随便糊弄过去,错失了宝贵的课堂学习机会,我就直接在 Ubuntu 上做了一遍
环境
我使用的是Ubuntu 24.04.4 LTS 64位 的虚拟机
- CPU:4 核
- 内存:8GB
- 硬盘:50GB
- 网络:NAT模式

实验开始前首先创建一个快照,这样哪怕系统崩了也可以随时恢复
安装工具,构建开发环境
|
|
为了防止后续步骤更新内核失败导致无法引导,备份/boot目录并保存内核版本信息
|
|
内核编译
获取源码
从Linux内核官方归档网站下载源码。我下载的是 5.15.148版本
|
|
解压源码
|
|
配置内核
为了确保新内核的配置与现在的系统兼容,最好的方法是拷贝现在内核的配置
拷贝当前系统的配置文件
|
|
生成新内核的配置文件,保留当前内核的配置,新增配置全部默认设置
|
|
修改证书
在Ubuntu中,上一步拷贝来的配置文件默认开启了内核签名校验,配置中引用了 Ubuntu 的证书文件路径,但源码里没有这些
.pem文件。如果不修改,编译很可能报错
为了避免编译失败,需要使用 scripts/config 脚本修改 .config
|
|
确认修改,这里如果看到如图的输出,说明修改成功
|
|

编译
查看可编译项
|
|
可以看到bzImage - Compressed kernel image (arch/x86/boot/bzImage),这就是编译生成的内核镜像

执行编译,这里 $(nproc) 是自动获取的 CPU 核数,这样可以同时运行多个编译任务,加快编译速度
执行命令进行编译前务必确认剩余存储大于20G,否则很可能由于存储不足导致编译失败,可以执行
df -h查看/分区
|
|
bzImage:内核名,计算机将大量.c源文件编译成二进制.o文件,最后输出一个压缩镜像文件bzImage,位于arch/x86/boot/bzImagemodules:驱动插件,如果将所有驱动都编译进内核会很臃肿,所以需要这个独立的插件。它编译为.ko文件(Kernel Object),平时存储在硬盘,只有插入对应硬件时,内核才会加载对应的驱动到内存
内核编译时间比较长,一般需要几十分钟甚至几小时
一段时间后可以看到编译完成
安装
编译完成后执行下面的命令,安装模块和内核镜像
Ubuntu的
make install会自动调用update-grub,执行完之后会自动把内核复制到/boot,并更新 grub 引导,不需要手动配置
|
|
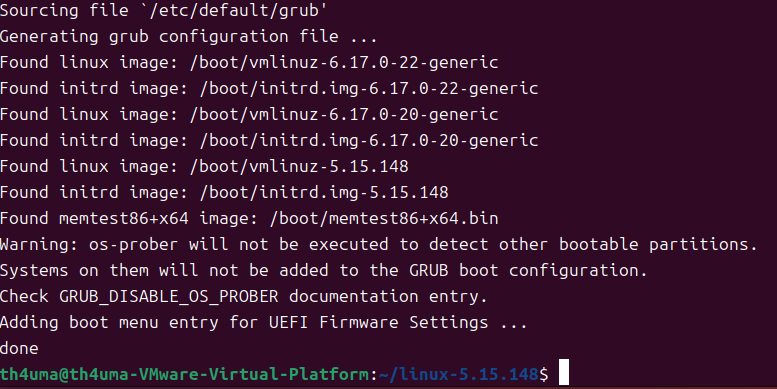
完成后重启系统
|
|
在GRUB引导菜单选择新内核启动,登录系统后验证版本
|
|
遇到问题:重启后没有进入GRUB菜单,无法选择启动项,还是进入了原来的内核

检查GRUB配置文件
1sudo nano /etc/default/grub可以看到GRUB菜单是隐藏的
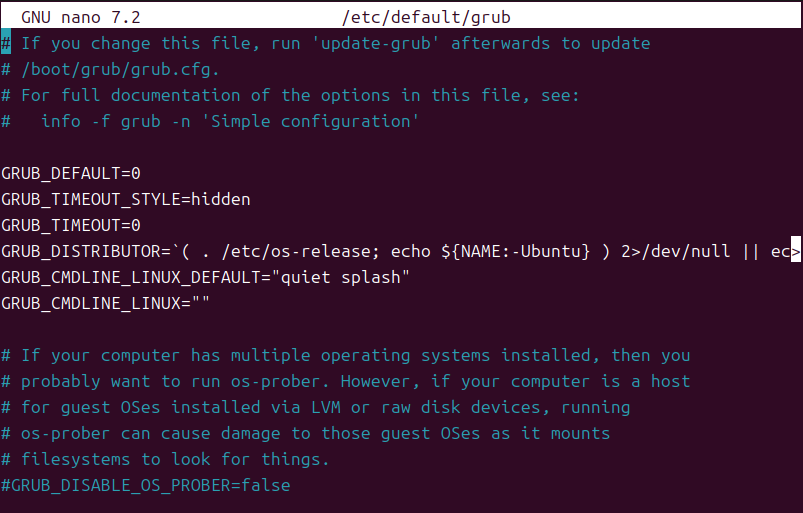
设置开机时显示10秒GRUB菜单:
GRUB_TIMEOUT_STYLE=menuGRUB_TIMEOUT=10更新配置使其生效
1sudo update-grub输出中有这一行
Found linux image: /boot/vmlinuz-5.15.148,说明内核确实安装成功了,只是刚刚默认进入了原来的内核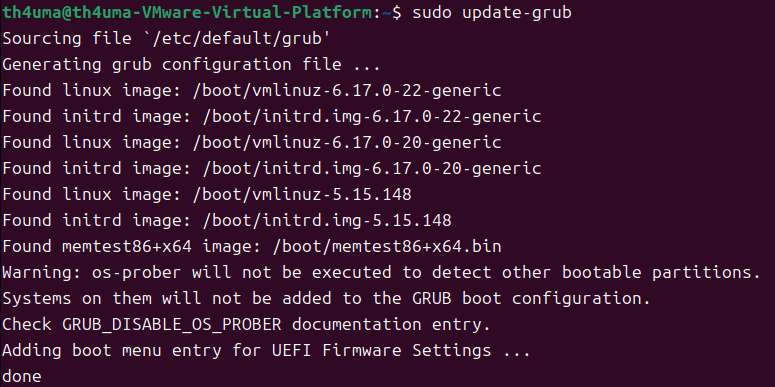
再次重启,在 GRUB 界面选择
Advanced options for Ubuntu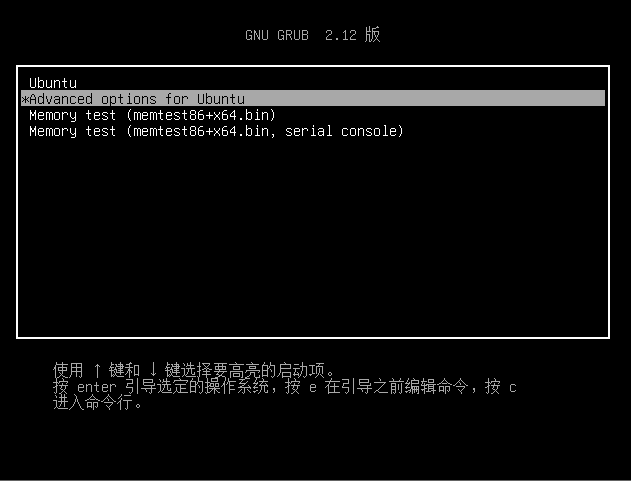
进入后,可以看到刚刚编译的内核
Ubuntu, with Linux 5.15.148,选中并回车,进入系统后重新输入命令进行验证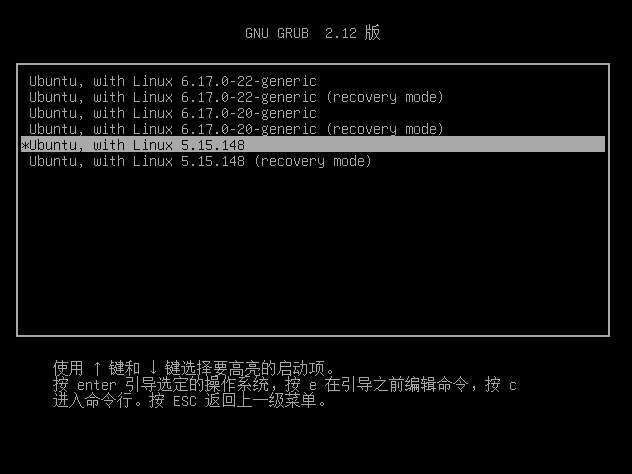
这里的输出是源码的版本号5.15.148,说明内核编译成功

添加 Linux 的系统调用
用户程序的权限不足,无法直接访问内核,系统调用就是用户程序以syscall作为接口,通过调用表的方式来间接调用内核执行功能
之后的操作均在linux源码所在目录中执行,进入源码目录
|
|
分配系统调用号
这一步是为系统调用在调用表中分配一个唯一编号,相当于一个指针
编辑 x86_64 的系统调用表文件
|
|
文件中有这一行don't use numbers 387 through 423, add new calls after the last'common' entry。在文件中找到common调用的末尾,可以看到截止到448号。我使用未被占用的450作为新的系统调用号
|
|

声明系统调用
这一步相当于在头文件启用函数的调用
编辑系统调用头文件
|
|
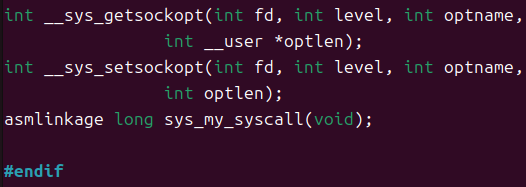
在文件末尾 #endif 之前,添加系统调用函数声明
|
|
实现系统调用
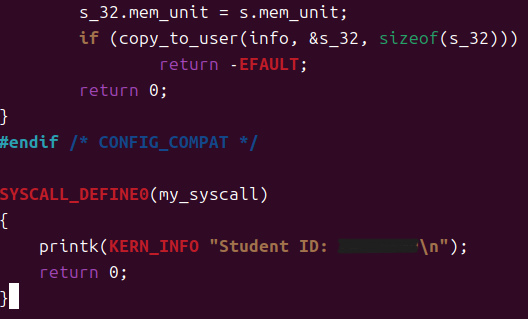
在 sys.c 文件末尾添加系统调用的代码
sys.c是内核存放系统调用的文件,在末尾添加可以避免影响现有代码
|
|
代码如下
|
|
SYSCALL_DEFINE0表示无参数printk相当于内核里的 printf- 输出在内核日志中,并不会在终端直接显示
重新编译内核
只是修改源码并不能在当前内核直接生效,重新编译安装才是真正将前面的修改添加进内核
|
|
重启后进入刚刚编译好的内核,GRUB中可以看到有两个相同版本号的内核,其中一个有.old后缀,这个就是修改源码前第一次编译的内核,选择没有后缀的内核进入
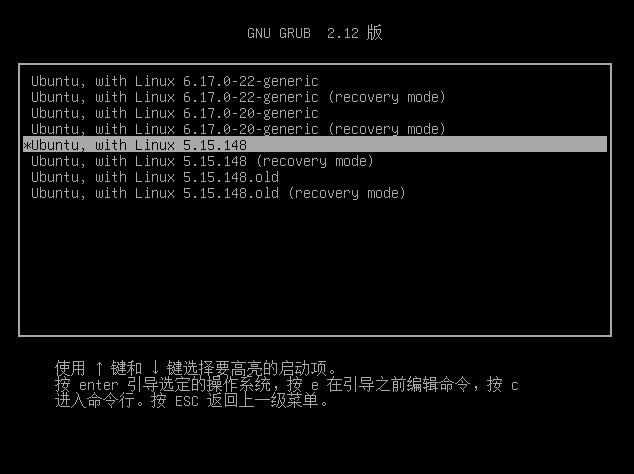
进行测试
创建一个测试程序 syscall_t.c
|
|
代码如下:
|
|
编译运行:
|
|
查看内核日志
|
|
grep后面应该写想要搜索的日志或输出中的关键词,而不是程序名。这一步需要加sudo,是因为普通用户默认不可访问内核日志
看到刚才 printk 的内容,就说明调用成功

现象:进入这个内核以后,图形界面一直特别卡,操作延迟在一秒左右,查看系统监视器,发现CPU的四个核心轮流占用百分百,某一个核心运行的时候其他的几乎不工作

可能原因:内核没有加载显卡驱动,桌面环境的所有图形计算都使用 CPU。而图形渲染是单线程,从而导致 CPU 满载。Linux 调度器会在不同 CPU 核之间迁移这个线程,也就是多个核心轮流100%占用
这是缺少图形驱动导致的性能问题,不是内核编译错误
实验成功后,在源码目录执行 make clean 清除编译文件
附:Ubuntu 和 openEuler 的差异
| 对比项 | openEuler (ARM64) | Ubuntu (x86_64) |
|---|---|---|
| 包管理器 | yum / dnf (RPM系) |
apt (Debian系) |
| 架构特定目录 | arch/arm64/ |
arch/x86/ |
| 内核镜像目标 | Image |
bzImage |
| 设备树 (DTB) | 需要编译 dtbs |
x86平台不需要编译 dtbs |
| 系统调用表位置 | include/uapi/asm-generic/unistd.h |
arch/x86/entry/syscalls/syscall_64.tbl |
| 调用约定 | 依赖ARM64特定的调用约定和寄存器 | 依赖 x86_64 调用约定与 SYSCALL_DEFINE 宏 |